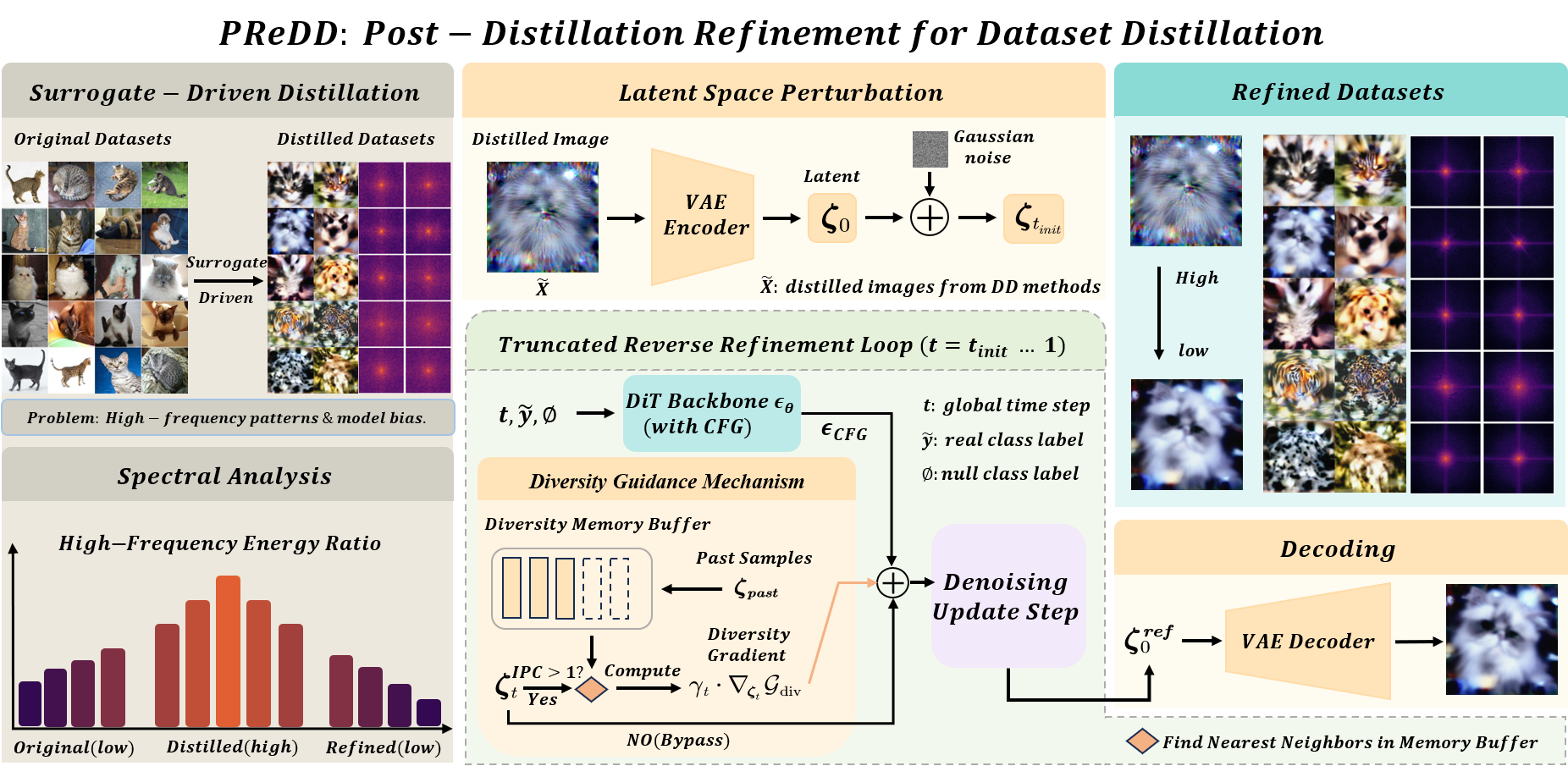
Dataset distillation compresses large datasets into compact synthetic subsets for efficient learning. However, existing methods often rely on specific surrogate models, resulting in undesirable high-frequency patterns and limited cross-architecture generalization. To address this issue, we introduce PReDD, a training-free and Post-distillation Refinement method that improves the quality of Distilled Datasets without retraining the original pipeline. PReDD encodes distilled images into the latent space of a pre-trained VAE and applies a truncated reverse diffusion process to refine them, effectively suppressing surrogate-induced high-frequency patterns while enhancing semantic content. Our method is model-agnostic and compatible with various distillation techniques. Extensive experiments demonstrate that PReDD consistently achieves state-of-the-art performance in cross-architecture evaluation, showcasing superior generalization in dataset distillation.




As shown in Figure above, a key limitation of surrogate-driven distillation is the emergence of excessive high-frequency patterns in synthetic images. We quantify these patterns using Fourier analysis by computing the ratio of spectral energy in the high-frequency band (normalized radial frequency r ≥ 0.5) and plotting its distribution across samples. Distilled datasets exhibit higher high-frequency energy than random, which correlates with degraded cross-architecture generalization. In contrast, PReDD reduces these patterns, producing spectra closer to or even lower than those of randomly chosen real samples. This improvement mitigates structural bias and enhances transferability across architectures.
Our contributions are summarized as follows:







Effect of Reverse Diffusion Steps
As shown above, MTT(left) consistently favors a shallow depth (K=10) for both IPC=1 and IPC=10, while DM(right) requires deeper refinement, peaking at K=15 for IPC=1 and K=20 for IPC=10. This is due to semantic quality differences: MTT produces class-consistent samples, so shallow refinement suffices, whereas DM generates weaker semantics with stronger high-frequency bias, benefiting from more reverse steps. Excessively large K may oversmooth details and harm generalization.

t-SNE Visualization
Fig. above shows a t-SNE visualization of feature embeddings for three selected classes in ImageNet-Fruits (10 IPC). Random samples are widely scattered with substantial overlaps, distilled samples are more compact but still suffer from noticeable inter-class mixing. In contrast, PReDD consistently produces clusters that are both compact within each class and well separated across classes, with minimal overlaps.
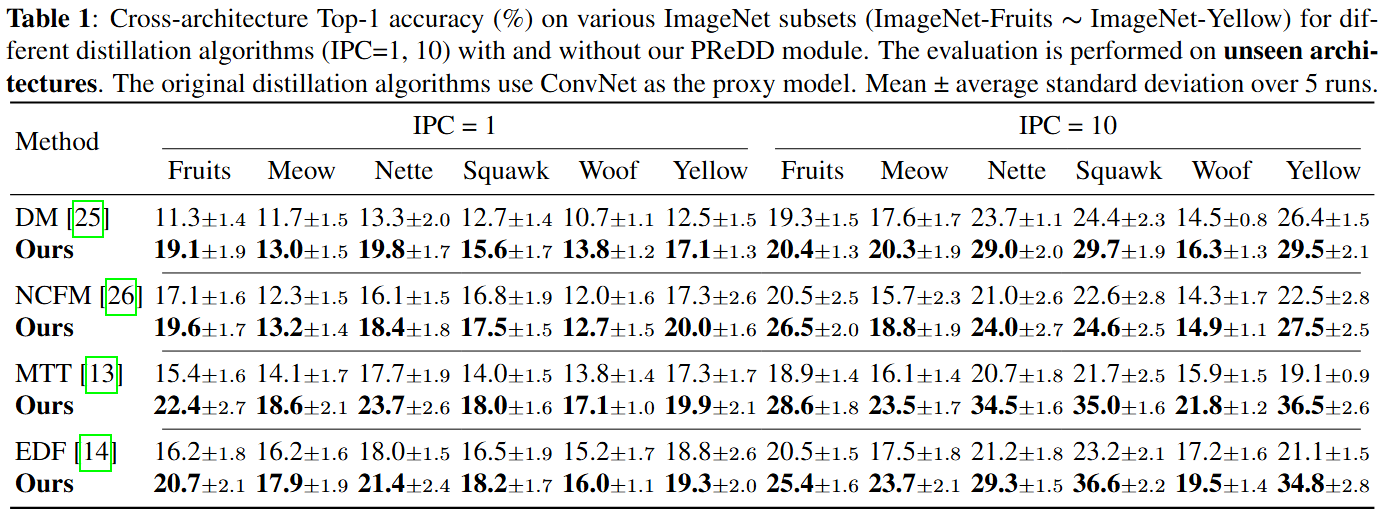
Cross-architecture Top-1 accuracy on various ImageNet subsets (IPC = 1, 10). Evaluation on unseen architectures, including ViT-b/16, EfficientNet, ShuffleNetV2, MobileNetV2, and ResNet18. Mean ± std over 5 runs.
Table above summarizes cross-architecture results on multiple ImageNet subsets under IPC=1 and 10. Across all baselines, our PReDD consistently improves generalization on unseen architectures. Gains are particularly pronounced on MTT, where improvements exceed +10% absolute in several settings (e.g., Yellow, Nette at IPC=10). This indicates that PReDD effectively reduces surrogate-induced bias and strengthens semantic consistency.
Coming Soon